
Le chameau symplectique
Bienvenu(e) sur cette magnifique série méta-mathématique constituée d’un gros total d’une (1 !) errance. (Quitte à commencer quelque part, j’ai préféré commencer à 1.)
“Je veux juste pouvoir le faire !”
L’idée était de comprendre comment réaliser un nuage de mots. Après en avoir vu beaucoup, souvent très jolis et parfois informatifs, j’avais envie de savoir comment les construire. Je n’avais aucune idée précise en tête sur le(s) texte(s) que je voulais illustrer, juste je voulais pouvoir le faire. Et j’étais bien persuadé que ce serait très difficile.
Et bien pas du tout. Faire un nuage de mots ayant une forme prédéterminée à partir d’un texte donné, c’est très facile. Ridiculement facile. Je ne mens pas, pour avoir un nuage de mots en forme de truc, il suffit de quelques librairies, d’un dessin de truc et de :
le_truc = np.array(Image.open("dessin_de_truc.png"))
wc = WordCloud(background_color="white", max_words=2000, mask=le_truc,
stopwords=non_pas_ceux-la_merci, contour_width=0,)
# generate word cloud
wc.generate(texte_plein_de_mots)
# store to file
wc.to_file("le_truc_plein_de_mots.png")
Ce bout de code extrait au plus 2000 mots du texte_plein_de_mots, en évitant ceux spécifiés dans la liste non_pas_ceux-la_merci et les place tout seul comme un grand dans la partie noire du dessin_de_truc. Le tout sur fond blanc et sans contour apparent parce que c’est plus joli comme ça — objectivement bien sûr.
Résultat : le_truc_plein_de_mots.png.
J’avais prévenu. Ridiculement facile.
Le plus dur est donc de trouver des textes subjectivement intéressants à partir desquels constuire ledit nuage, idéalement en forme de truc pertinemment choisi. Ma chère et tendre m’a d’abord suggéré d’utiliser les babillages de notre fils (environ 1.585 an à un jour près au moment d’écrire ces lignes). L’idée m’a fait sourire mais je ne l’ai pas retenue pour un premier nuage de mots principalement parce que “mots” ne s’applique pas littéralement dans ce cas (bien que “nuage” si quelque part), et que 2000 (même pseudo-) mots c’est autour de 100 fois trop.
Trouver des textes.
Ce n’est probablement pas par coïncidence que l’idée d’extraire les textes en question de l’arXiv m’est venue un beau matin, durant l’absorption de mon premier expresso double, à la réception du mail quotidien intitulé math daily Subj-class mailing. Une fois l’idée générale émergée, il ne m’a pas fallu plus d’un second expresso double pour avoir l’idée précise : rassembler les titres et résumés de tous les articles soumis en géométrie symplectique en 2019, et en extraire un nuage de mots. En forme de chameau évidemment.
Extraire les métadonnées d’articles de l’arXiv est, sinon aisé, possible et même encouragé, si c’est bien fait. En particulier, il y a quelques règles de bienséance à respecter : aller sur le serveur dédié à ce genre de requêtes, attendre suffisamment entre deux requêtes successives, limiter le nombre d’articles par requête etc. Bref. Que du bon sens, qu’il est toujours bon d’expliciter. Une fois ces règles lues, il est facile d’engendrer un fichier xml contenant les données recherchées, que l’on peut récupérer sous forme de chaîne de caractères via
import urllib.request as libreq
with libreq.urlopen('http://export.arxiv.org/api/query?search_query=cat:math.SG&start=6402&max_results=454&sortBy=submittedDate&sortOrder=ascending') as url:
r = url.read()
On remarquera au passage que je n’ai pas réussi à limiter les résultats de la recherche aux articles soumis en 2019. Dans mon impatience, j’avoue ne pas avoir cherché très longtemps et préféré déterminer par essai-erreur le premier article de la série (math.SG, ordonnée par date de soumission) puis le dernier. En passant, ça fait 454 articles qui avaient pour catégorie primaire ou secondaire math.SG en 2019. Pour comparaison, il y en avait 326 en 2009 (cf. une suite de cette première partie, pas encore écrite, pour plus de comparaisons entre 2009 et 2019).
Attention : information inutile ! Le premier article soumis en 2019 est de Zongrui Yang, et le dernier de Sheel Ganatra. #OnVousAvaitPrevenu
Retournons aux nuages. Il suffit maintenant de casser la chaîne de caractères r en une liste de chaînes, chacune d’elles correspondant à un article, de transformer cette liste en liste de dictionnaires avec la librairie xmltodict, et d’assembler ces dictionnaires en un joli DataFrame de chez pandas (dont on a expurgé un certain nombre de champs a priori inutiles pour ce que l’on veut en faire — même à moyen terme).
Trouver un chameau chamadaire.

C’est de loin l’étape la plus facile : je l’ai dessiné en m’inspirant d’une recherche sur Gogol-images. Comme il suffit de la forme extérieure, une courbe de bézier suffisamment travaillée dans inkscape donne très vite un résultat sympa.
Alors oui… je sais que ce n’est pas un chameau mais un dromadaire. Cela dit, à ma décharge, je fais des maths en anglais et … les chameaux que j’ai fumés pendant toute ma jeunesse avaient cette forme là. Ça marque un esprit. Et des poumons.
Finalement ! Créer le nuage de mots.
La dernière étape de la preuve (déformation professionnelle) consiste en l’exécution du code ci-dessus, avec un texte constitué des titres et résumés des articles dont on a récupéré les métadonnées sur l’arXiv (dans les faits, je me suis restreint aux articles pour lesquels math.SG est la catégorie primaire), et en appliquant le masque chamadaire dessiné.
Ok. Après la première tentative, il faut aussi retravailler la liste non_pas_ceux-la_merci des mots à enlever. De fait, et pour une raison proprement évidente, “mathbb” et “mathcal” mais aussi “show”, “prove”, “obtain” (par exemple !) ne sont pas dans la liste standard de mots déraisonnables à indexer mais sont particulièrement fréquents dans le texte considéré et peu pertinents pour nos fins… Bref. Après petits travaux de peaufinage du texte :
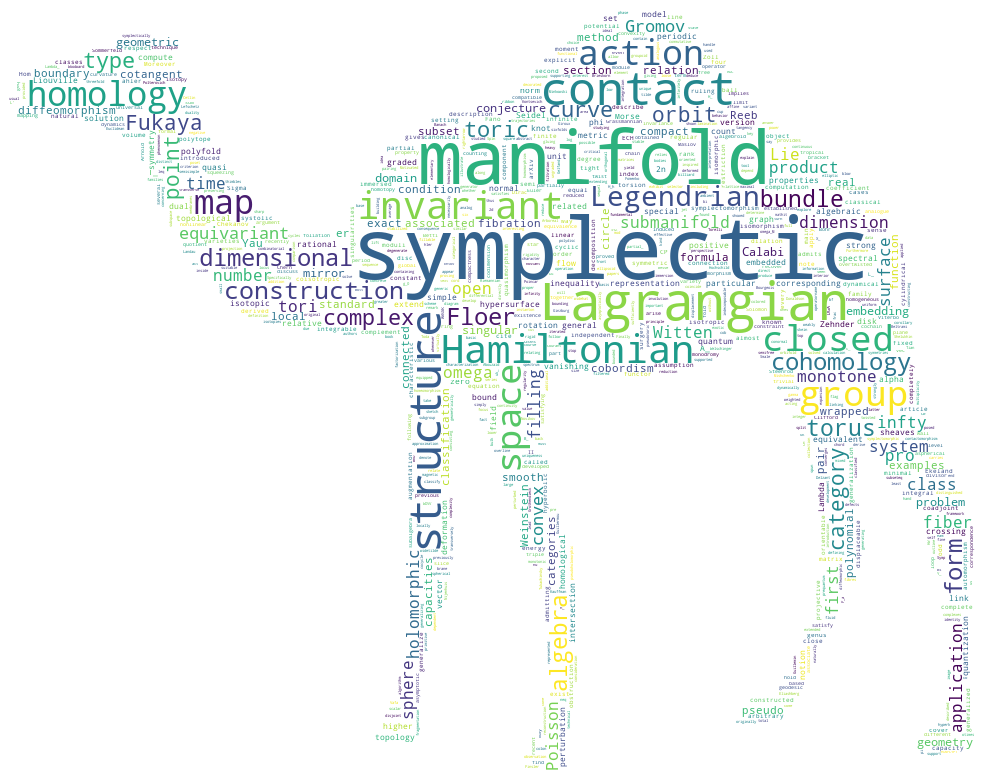
Conclusion.
Ce n’est qu’un premier essai, il y a (évidemment) encore beaucoup (euphémisme) de choses à explorer et de parenthèses à ouvrir (mais pas dans cette phrase-ci qui en contient déjà beaucoup). En particulier, il y a l’option de permettre aux couples de mots très utilisés d’apparaître, mais il est un peu plus difficile d’enlever ceux qui sont hors de propos et très très (très) usités, du type “we prove”, “we show”, “in particular”, “existence of”, etc. C’est dommage parce si l’on voit autant de Gromov–Witten et de Calabi–Yau en 2019 qu’en 2009, on voit définitivement appraître de plus en plus de Fukaya category et de mirror symmetry en 2019.
Coïncidence ?! Tous les mots que je connais pour lesquels le français est plus efficace que l’anglais sont rassemblés dans cette expression : “mirror symmetry”. #Mefiance
Je vais aussi reproduire l’expérience en retirant les mots trop “à la base” du domaine (“symplectic”, “contact”, “manifold”, “submanifold”, “form”, “dimensional”) pour permettre aux autres (décrivant les techniques utilisées) d’apparaître. J’imagine que comparer les chamadaires de 2009 et 2019 pourra être amusant sinon informatif. J’ai plein d’autres idées de choses à faire avec les métadonnées extraites de l’arXiv…
Side(& site)-products.

C’est en cherchant à faire le chamadaire symplectique que m’est venu le canard du même nom qui sert de logo à ce blog. Le principe est le même, le masque est un canard (si si), et le texte est constitué des titres et résumés de mes articles (et autres textes non publiés).
C’est ce logo qui a ensuite donné le nom au blog. C’est dire que j’en suis content…
 Pour finir, je n’ai pas pu résister devant un petit WordCloudeption : la page nuage de mots (Wikipedia, en) dans un nuage de mots, en forme de nuage (que j’ai dessiné moi-même — quel talent !).
Pour finir, je n’ai pas pu résister devant un petit WordCloudeption : la page nuage de mots (Wikipedia, en) dans un nuage de mots, en forme de nuage (que j’ai dessiné moi-même — quel talent !).
The end.